Introducción a ELK (Elasticsearch, Logstash y Kibana) (parte 2)
|
Vamos a hacer algo útil con los datos que tenemos sin modificar mucho el ejemplo anterior. La salida, en vez de ir a un correo vamos a meterla en Elasticsearch para luego poder hacer consultas con Kibana. Hay multitud de tutoriales en internet así que no me voy a extender mucho en el cómo hacerlo sino en qué cosas puede hacer que funcione mejor en base a mi experiencia en los casi dos años que llevo usándolo. |
|
¿Cómo funciona?
El esquema será el que ilustra la imagen de la portada donde se ve el flujo de los datos.
Esta imagen no refleja el cómo los datos viajan de un lado al otro y eso es lo que realmente hace falta entender así que ahí va la misma imagen ligeramente retocada:
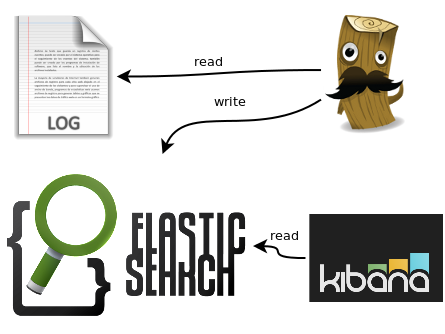
Como ves hay dos almacenes (log y elasticsearch) en los que están los datos que nos interesan y dos piezas de software (logstash y kibana) que hacen transformaciones con ellos y los mueven o los muestran como nosotros queremos.
Logstash
Si has seguido las instrucciones del artículo anterior ya lo tienes instalado.
Para acceder a los logs que necesitamos es necesario que se ejecute como root así que ve a /etc/default/logstash y pon LS_USER=root.
Dado que va a leer de los logs en este caso (aunque podría leer desde otro sitio) y escribir en elasticsearch necesitamos saber cómo son los logs de los que vamos a leer y cómo meter los datos en elasticsearch.
read
La primera parte es la más peliaguda porque cada aplicación tiene un log distinto pero hay un par de cosas que tendremos que tener en cuenta siempre:
- Formato de la hora que usa la aplicación para escribir en el log
- Datos que podemos querer consultar del log
timestamp
Me viene a la cabeza el log de squid donde la hora viene en el primer campo en segundos desde 01/Ene/1970 (fecha epoch) hasta la del apache donde viene en formato legible en el cuarto campo pasando por las de diversas aplicaciones que guardan el día y la hora en dos campos distintos separados por un pipe "|".
Si queremos hacer una consulta del estilo "¿qué paso esta noche a las 3 de la madrugada?" necesitamos que logstash sea capaz de entender todos esos formatos de hora para poder insertarlos en la base de datos con el mismo timestamp.
fields
Pongamos por caso que tenemos el log de apache siguiente:
127.0.0.1 - - [20/Jul/2013:08:16:58 +0200] "POST /my/machines HTTP/1.1" 404 443 "-" "-"
Si utilizamos como separador de campo los espacios veremos que nos meterá la fecha en dos campos y eso no es lo que queremos. Tampoco podemos separar campos utilizando comillas porque no todos los campos tienen comillas así que hay que gestionar esto de una forma más inteligente.
write
En este caso concreto es bien fácil, ya que existe el output elasticsearch al que le indicamos donde está la base de datos y el resto lo gestiona él.
Hay dos cosas a tener en cuenta:
- Utilizar el plugin de elasticsearch con protocol => "http" para utilizar el API Rest de la base de datos. De esta forma ante una actualización de logstash o la base de datos, es menos probable que se rompa la aplicación.
- logstash crea una base de datos diaria y realiza muchos accesos a disco lo cual, tras meses de uso, puede desembocar en problemas para el sistema operativo que se tratarán en la sección de elasticsearch.
Ejemplo completo: SpyYourFriend
Queremos poder responder a la siguiente pregunta: ¿cuando se eliminó el directorio /var/www/kibana del servidor y quien lo hizo?
Vamos a utilizar como fuente de datos el .bash_history y el /var/log/auth.log.
Pasos:
- Configurar la bash para que agregue líneas en el history cada vez que se pulsa el enter y que ponga la fecha de cada comando en el log.
- Configurar logstash para extraer los campos de cada log e insertar la información en la base de datos.
Configurar la bash
No me extiendo mucho. Simplemente agrega esto al .bashrc de root:
export HISTTIMEFORMAT="%F %T " export PROMPT_COMMAND='history -a'
Con esto dejaremos el timestamp de cada comando en /root/.bash_history y forzaremos a escribir en el history cada vez que tecleamos un comando en vez de al hacer logout.
Configurar logstash para extraer datos de /var/log/auth.log
Vamos a introducir la variable type que utilizaremos para "etiquetar" un flujo y poderle dar un trato diferencial a lo largo del archivo de configuración de logstash. A tener en cuenta:
- Entrada: líneas del archivo en "/var/log/auth.log"
- Proceso: extraer campos y configurar timestamp.
- Salida: enviar todo a elasticsearch.
input {
file {
type => "auth"
path => "/var/log/auth.log"
}
}
filter {
# This is a standard syslog line like this:
# Mar 9 17:17:02 path-precise CRON[25638]: pam_unix(cron:session): session closed for user root
if [type]=="auth" {
# Look for patterns in /opt/logstash/patterns/grok-patterns
grok {
match => [ "message", "%{SYSLOGLINE}" ]
}
# Set timestamp: http://logstash.net/docs/1.4.1/filters/date#match
date {
match => [ "timestamp", "MMM dd HH:mm:ss",
"MMM d HH:mm:ss",
"ISO8601" ]
}
}
}
output {
elasticsearch {
protocol => "http"
host => "localhost"
}
}
Este es el ejemplo más sencillo que puede haber pero se puede complicar bastante. Pasemos al ejemplo siguiente.
Configurar logstash para extraer datos del history
El archivo de history tiene una pinta como esta:
root@yinyan-precise:~# tail .bash_history #1403070049 history #1403070054 ls #1403070056 history #1403070062 cd #1403070066 more .bash_history root@yinyan-precise:~#
donde como se puede observar el timestamp está escrito en formato epoch precedido por un "#" y además el comando está en la siguiente línea. Esto último seguro que te recuerda al catalina.out del tomcat donde cada "línea" de log está compuesta de múltiples líneas.
- Entrada: /root/.bash_history
- Proceso:
- Juntamos las dos líneas en una sola eliminando '\n' y '#'
- Extraemos el campo de la fecha y el de la línea de comandos
- Utilizamos la fecha en formato epoch para poner valor al timestamp
- Agregamos un campo con la línea en formato más legible
- Salida: Elasticsearch
Agárrate que vienen curvas:
input {
file {
type => "bash_history"
path => "/root/.bash_history"
}
}
filter {
if [type]=="bash_history" {
# Poner las dos líneas como una sola en el campo message
multiline {
pattern => "^#"
what => "next"
}
# Cambiar fecha del principio
# Vamos a separar los campos eliminando el retorno de carro y el comentario
mutate {
add_field => ["temp_message", "%{message}"]
}
mutate {
gsub => [
"temp_message", "\n", " ",
"temp_message", "^#", ""
]
}
grok {
match => [ "temp_message", "%{WORD:unix_date} %{GREEDYDATA:command_line}"]
}
mutate {
remove_field => ["temp_message"]
}
# Copio el contenido del timestamp a otra variable para conservar el momento
# en que el mensaje llegó al servidor de logstash
mutate {
add_field => [ "input_timestamp", "%{@timestamp}" ]
}
# Sobreescribo el timestamp con la fecha que pone en el archivo de log
date {
match => [ "unix_date", "UNIX"]
}
mutate {
remove_field => ["unix_date"]
}
# Agrego un campo con la línea en formato legible
mutate {
add_field => [ "human_readable_message", "%{@timestamp} %{command_line}" ]
}
}
}
output {
elasticsearch {
protocol => "http"
host => "localhost"
}
}
Toda la configuración junta
input {
file {
type => "auth"
path => "/var/log/auth.log"
}
file {
type => "bash_history"
path => "/root/.bash_history"
}
}
filter {
# This is a standard syslog line like this:
# Mar 9 17:17:02 path-precise CRON[25638]: pam_unix(cron:session): session closed for user root
if [type]=="auth" {
# Look for patterns in /opt/logstash/patterns/grok-patterns
grok {
match => [ "message", "%{SYSLOGLINE}" ]
}
# Set timestamp: http://logstash.net/docs/1.4.1/filters/date#match
date {
match => [ "timestamp", "MMM dd HH:mm:ss",
"MMM d HH:mm:ss",
"ISO8601" ]
}
}
if [type]=="bash_history" {
# Example: "#1403708872\n tar -zxvf kibana-3.1.0.tar.gz "
# This is a multiline log. Set message var with both lines.
multiline {
pattern => "^#"
what => "next"
}
# Split fields. First field unix_date until first space. Second field command line after first space.
# Use aux var temp_message.
mutate {
add_field => ["temp_message", "%{message}"]
}
# temp_message=="#1403708872\n tar -zxvf kibana-3.1.0.tar.gz "
# Remove \n and #
mutate {
gsub => [
"temp_message", "\n", " ",
"temp_message", "^#", ""
]
}
# temp_message=="1403708872 tar -zxvf kibana-3.1.0.tar.gz "
# Set unix_date and command_line
grok {
match => [ "temp_message", "%{WORD:unix_date} %{GREEDYDATA:command_line}"]
}
mutate {
remove_field => ["temp_message"]
}
# unix_date=="1403708872"
# command_line=="tar -zxvf kibana-3.1.0.tar.gz "
# Set input_timestamp to the timestamp when the log line is processed by logstash
mutate {
add_field => [ "input_timestamp", "%{@timestamp}" ]
}
# Set timestamp and remove temporal var unix_date
date {
match => [ "unix_date", "UNIX"]
}
mutate {
remove_field => ["unix_date"]
}
# Add a field with the log line in human readable format
mutate {
add_field => [ "human_readable_message", "%{@timestamp} %{command_line}" ]
}
}
}
output {
elasticsearch {
protocol => "http"
host => "localhost"
}
}
Elasticsearch
Su instalación consiste en bajarse el paquete de aquí e instalarlo.
En el siguiente post haré un monográfico de elasticsearch. De momento sólo diré que para enviar la información a la base de datos hay que poner esto en el output:
output {
elasticsearch {
protocol => "http"
host => "localhost"
}
}
Kibana
Yo lo defino como un visualizador gráfico de consultas lucene que sirve para hacer búsquedas que no sabes que vas a hacer hasta que las haces.
Esto te da una enorme flexibilidad pero no te permitirá hacer unos buenos informes. El tema de los informes se tratará más adelante en el siguiente post.
Instalación y ejecución
En versiones anteriores Kibana era una aplicación Ruby que funcionaba sobre Sinatra en el servidor. Ahora es una aplicación que se ejecuta enteramente en el navegador, lo que significa que desde tu navegador hará falta acceso a la base de datos (se puede restringir).
Bájate el kibana de aquí, lo descomprimes en /var/www/ y en config.js escribe la url que vas a poner en el navegador para acceder a tu servidor de elastisearch.
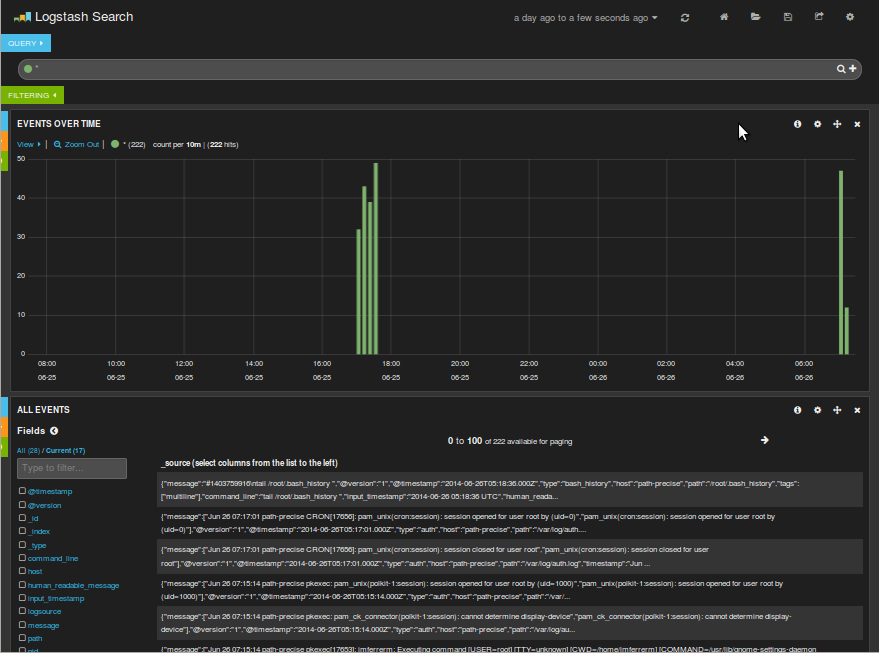
SpyMyFriend en funcionamiento
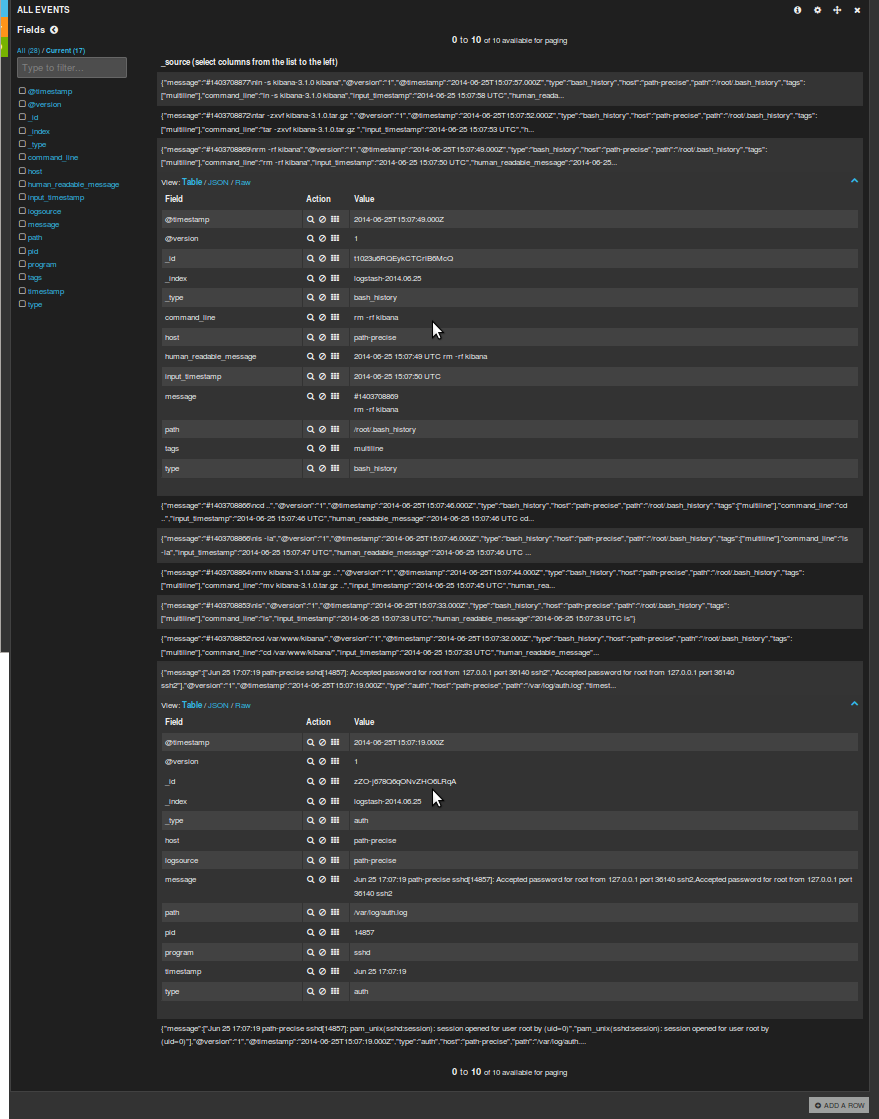
Si abrimos en el navegador la url donde hemos descomprimido el kibana y pinchamos en "here" veremos como tanto las líneas del auth que nos indican el momento y el origen de la conexión por ssh al servidor como los comandos que se han ido ejecutando han sido correctamente indexados.
Hacer búsquedas es bastante sencillo ya que se usa la sintaxis de lucene así que no hay que saber acerca de cómo funciona la base de datos que hay detrás. Si queremos buscar cuando se ejecutó un rm basta con poner "rm" y lo buscará.
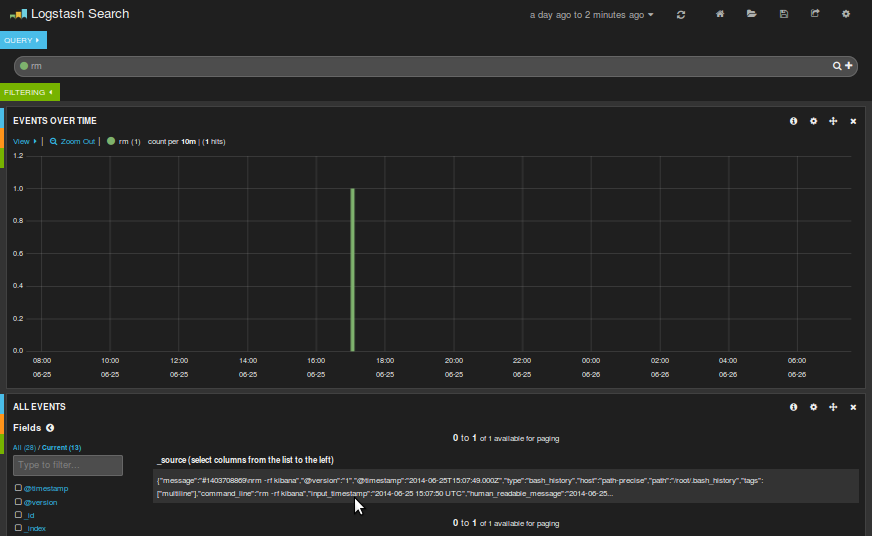
Si pulsamos en el evento nos saldrá una descripción de los campos con sus valores, lo que nos dará una idea para hacer más búsquedas:
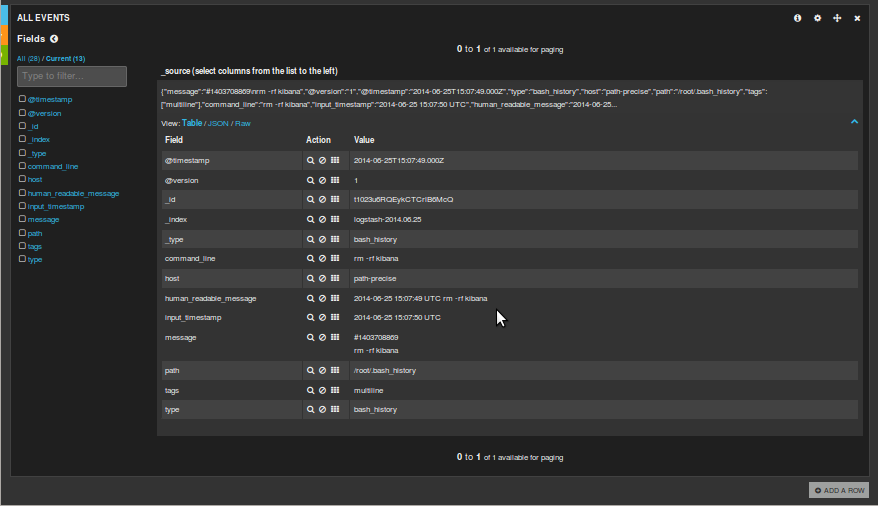
Ahí vemos que la búsqueda "correcta" hubiera sido command_line:"*rm*"
Ahora vamos a poner en verde las líneas del auth.log, en amarillo las del bash_history y en rojo la línea donde se ha borrado el kibana.
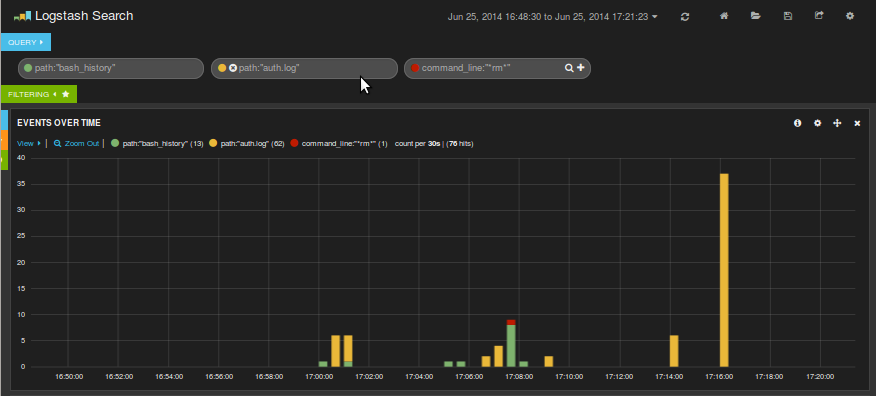
Sigue habiendo mucho ruido. De las líneas del auth.log nos interesan las que nos indican una conexión por ssh:
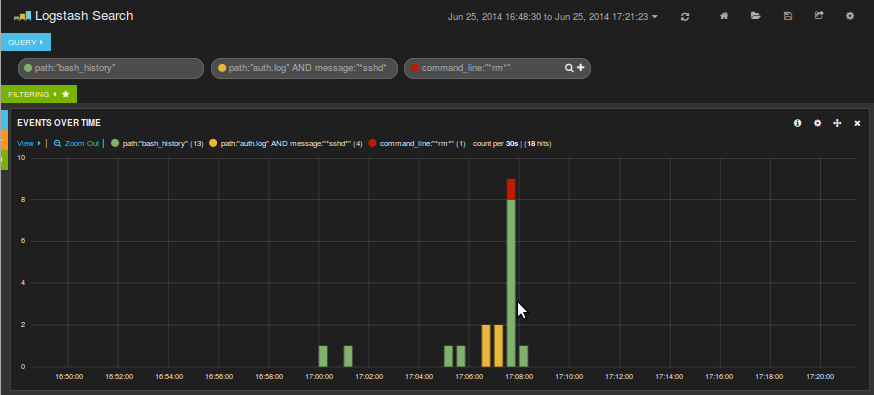
Al parecer tras hacer el estropicio quien sea se dejó la sesión abierta porque tras hacerlo no hay actividad en el auth.log de cierre de sesión ssh.
Encontramos actividad de ssh en el auth a las 17:06 y que luego se han tecleado una serie de comandos. Ampliamos la parte que nos interesa:
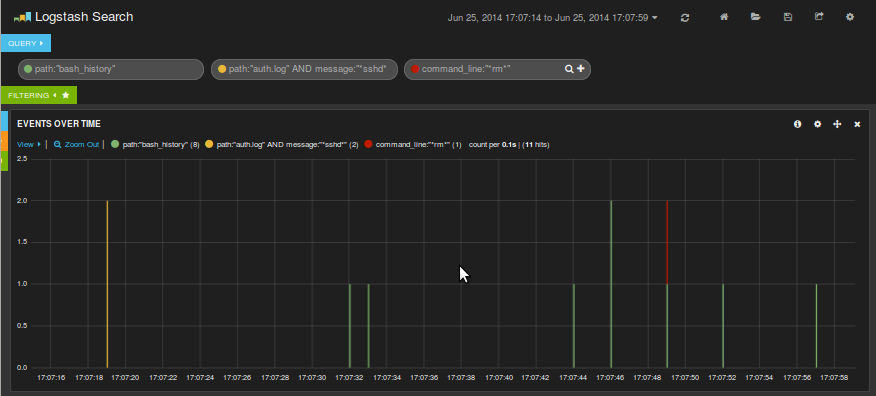
Ahora vamos a los eventos y vemos que alguien se conectó desde 127.0.0.1 y seguidamente estuvo trasteando con la instalación de kibana pero que luego la dejó bien. ¡Oh sorpresa! ¡He sido yo mismo!
Anotaciones
Este ejemplo, sobre todo la parte del bash_history, es bastante complicado pero si lo has entendido y lo has repetido en tu computadora te puedes considerar un usuario con experiencia de logstash y kibana.
Existen otras alternativas a logstash como por ejemplo fluentd que también es bastante popular. Entiendo que una vez entiendas cómo funciona logstash podrás hacer extensible ese conocimiento al resto de alternativas tanto libres como privativas.
Elasticsearch es un mundo en si mismo así que lo dejo para el siguiente post en el que intentaré hacer un "mapeo" entre SQL y NoSQL (mongodb y elasticsearch) ya que si nunca has usado una base de datos NoSQL pero eres un experto en SQL siento decirte que de NoSQL no tienes ni idea. Cambia tanto la filosofía a nivel de sistemas como a nivel de desarrollo.
Espero que este post os ayude.