En Andago tenemos dos cabinas de disco a las que se puede acceder físicamente desde distintos servidores y estamos empezando a montar raid1 entre las mismas.

Hace poco estuve a punto de cargarme toooda la información de los buzones de correo de la empresa. Bueno, de hecho me la cargué pero tuve reflejos para salir del paso y el correo solo dejó de funcionar media hora.
Tenía un raid entre las dos cabinas de los dispositivos de disco.
Instalé mdadm en un servidor de archivos con acceso a las cabinas de disco y vi:
beleg:~# more /proc/mdstat
Personalities : [raid1]
md2 : active raid1 etherd/e1.1p3[1] etherd/e0.0p4[0]
195312384 blocks [2/1] [U_]
[======>..............] recovery = 31.7% (165952/195312384) finish=0.4min speed=11853K/sec
unused devices:
beleg:~#
Dos dispositivos MD usados desde dos servidores distintos.
El servidor de disco había detectado el raid del de los buzones, lo había activado y lo estaba sincronizando -> corrupción de datos.
¡Arráncalo como sea Carlos, por Dios!
Piensa, piensa, piensa rápido. ¿Que se puede hacer? ¿Que se ha perdido? ¿Que no se ha perdido?
Primero: fui corriendo a la sala de máquinas a desconectar los cables del servidor de disco (y dns, proyectos y unas cuantas cosas más). La tabla de inodos sigue intacta en la memoria del servidor de correo. Una de las dos cabinas tiene la información correcta pero la otra tiene basura.
Segundo: Aviso al jefe de la empresa del problema con el correo y de su indisponibilidad durante un buen rato. Luego puse como solo lectura el dispositivo de buzones. Si está corrupto mejor no corromperlo mucho más.
Tercero: Tenía una copia desactualizada de todos los buzones -> rsync a la copia vieja.
Cuarto: Uno de los dos discos del raid está corrupto y el otro no ¿cual será? supondré que el bueno es el primero de los dos así que marco como malo el segundo, reinicio el servidor de correo ... y cruzo los dedos.
Quinto: El raid arranca degradado pero el servicio vuelve a funcionar normalmente así que se vuelve a añadir el dispositivo marcado como malo al raid.
La causa del problema
Al instalar el paquete mdadm, en el script de postinstalación se descubren todos los dispositivos MD, se configuran y se arrancan. Si alguno lo está usando otra máquina lo arranca igualmente provocando la corrupción de datos.
Entrando en detalle, en la línea 57 del postinst se llama al programa /usr/share/mdadm/mkconf que en su línea 57 se hace un --examine --scan si o si para configurar el mdadm. Esto de por si no tiene porque provocar ningún problema pero si se arrancara sería algo malo.
En un sistema en producción siempre es preferible que no se descubra nada a menos que se indique de forma explícita.
La solución
En realidad hay dos soluciones.
La primera y mejor es crear un archivo de configuración "vacío" en /etc/mdadm/mdadm.conf. De esta forma el script de postinstalación ve que ya existe y no intenta crearlo ni descubrir los dispositivos.
La segunda y peor consiste en decirle que "none":
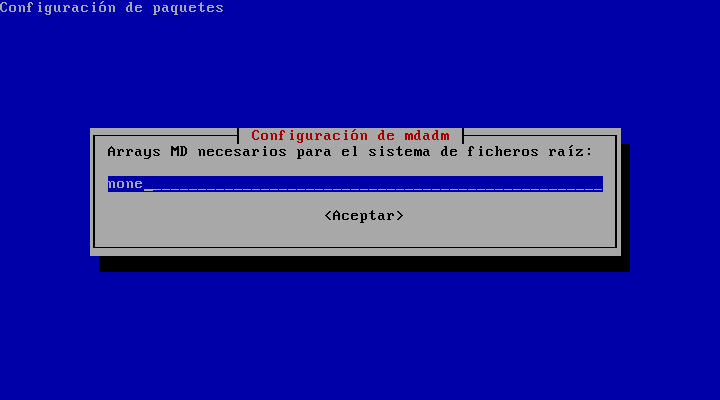
Y que no arranque MD al inicio:
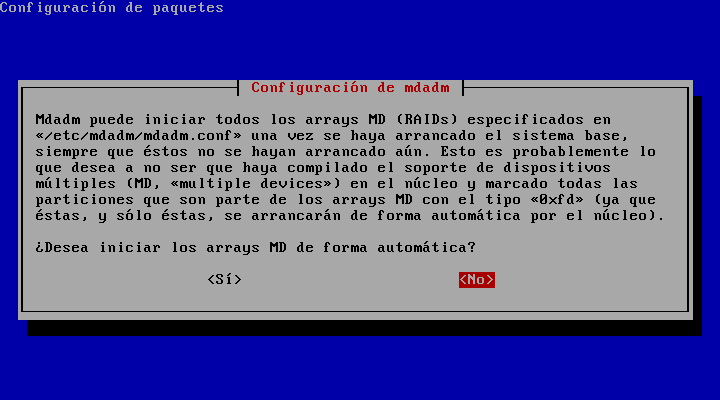
Más adelante se puede modificar la configuración del raid y activarlo en /etc/default/mdadm.