|
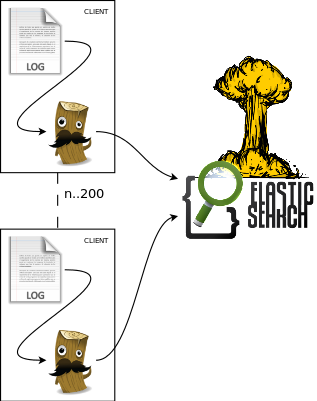
En todas las aplicaciones que he conocido el cuello de botella siempre ha estado en el mismo sitio: el almacenamiento. Puedes poner 20 frontales web y 20 servidores de aplicación pero en la capa de persistencia tiene que haber un almacenamiento compartido que puede provocar verdaderos quebraderos de cabeza y muchas noches de insomnio al sysadmin de turno. |
|
Para entender la problemática vamos a ver que tiempos manejamos en un entorno típico con mysql y cómo escalamos con Elasticsearch. En los siguientes artículos de SQL vs NoSQL entraré más en el detalle. En este artículo sólo quiero que se entienda la problemática y cómo se podría "resolver" con Elasticsearch.
Más rápido por favor
Imaginémonos que usamos mysql en mi portátil manejando unos tiempos de 0.01 segundos por inserción:
mysql> create table `tabla` (`id` varchar(5) NOT NULL, `data` varchar(5), primary key(`id`));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into `tabla` values ("1","2");
Query OK, 1 row affected (0.01 sec)
mysql> insert into `tabla` values ("2","2");
Query OK, 1 row affected (0.00 sec)
mysql> insert into `tabla` values ("3","2");
Query OK, 1 row affected (0.00 sec)
mysql> insert into `tabla` values ("4","2");
Query OK, 1 row affected (0.02 sec)
mysql>
Eso nos da una capacidad máxima de 100 inserciones por segundo que podrá parecer mucho pero ahora imagínate 10 servidores enviando líneas de log a razón de 10 por segundo de forma simultánea y verás como no te parece tanto.
Con elasticsearch dentro de una máquina virtual con discos de portátil estoy sacando unas 300 inserciones por segundo. Está mejor pero también tenemos un techo.
Soluciones SQL
Usar el típico entorno de replicación de mysql no soluciona el problema porque tenemos más escrituras que lecturas. En todo caso lo empeoraría porque la base de datos estaría más tiempo ocupada enviando datos a sus réplicas.
También podríamos tener varios servidores de mysql e ir enviando las líneas de log en roundrobin pero eso obligaría al software que va a explotar esos datos a hacer una gestión extra.
Además, al utilizar SQL, el software que va a insertar y explotar esos datos está obligado a cambiar el esquema de la base de datos cada vez que haya un cambio de un campo en un archivo de log.
Solución Elasticsearch
Elasticsearch es un gestor de bases de datos NoSQL que para el caso que nos ocupa tiene tres ventajas:
- Todos son maestros: En un grupo de replica (replica set) puedes insertar datos en cualquier servidor que ellos se las apañarán para replicarlos en los demás.
- Inserción asíncrona: Se envían los datos a la base de datos y el servidor te da el OK antes de hacer la inserción real en la base de datos y replicarlo al resto. Esto reduce muuuuucho los tiempos de inserción aunque crea otros problemas de latencia que en este dominio nos dan exactamente igual.
- Sin esquema: en una misma "tabla" puedes insertar "filas" con diferentes esquemas lo que posibilita poder insertar líneas de log desde diferentes orígenes. Pongo tabla y filas entre comillas porque ni las tablas se llaman tablas ni las filas se llaman filas, pero ya lo veremos en un artículo posterior.
Solución escalable
"Solucionando" cuellos de botella
En esta solución utilizaremos un servidor de redis que es otro gestor NoSQL (¡sorpresa!) utilizado como catalizador para que el logstash que almacena los datos en elasticsearch no explote. Se usará como un gestor de colas donde los agentes irán metiendo líneas de log desde los servidores y logstash las irá recogiendo para insertarlas en la base de datos.
De esta forma conseguimos:
- Paliar el problema con el cuello de botella en la base de datos.
- Monitorizar cuando nos vamos quedando sin capacidad mirando la longitud de la cola en redis. Por ejemplo haciendo un plugin de Zabbix que mire el tamaño de la cola de redis y nos devuelva un número que luego se podrá representar en una gráfica. Si el número supera un umbral. ¡alerta, necesitamos más capacidad!
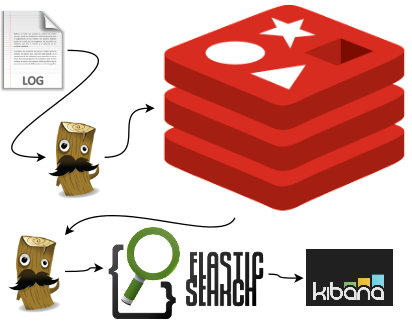
Visto en código suponiendo que tomamos los datos de un apache en el agente fíjate en el output:
input {
file {
type => "auth"
path => "/var/log/auth.log"
}
}
filter {
# This is a standard syslog line like this:
# Mar 9 17:17:02 path-precise CRON[25638]: pam_unix(cron:session): session closed for user root
if [type]=="auth" {
# Look for patterns in /opt/logstash/patterns/grok-patterns
grok {
match => [ "message", "%{SYSLOGLINE}" ]
}
# Set timestamp: http://logstash.net/docs/1.4.1/filters/date#match
date {
match => [ "timestamp", "MMM dd HH:mm:ss",
"MMM d HH:mm:ss",
"ISO8601" ]
}
}
}
output {
redis {
host => "localhost"
}
}
Y en el servidor de logstash fíjate en input:
input {
redis {
host => "localhost"
}
}
output {
elasticsearch_http {
host => "127.0.0.1"
}
}
Podríamos tener múltiples agentes disparando al mismo redis y de ahí viene la solución oficial:
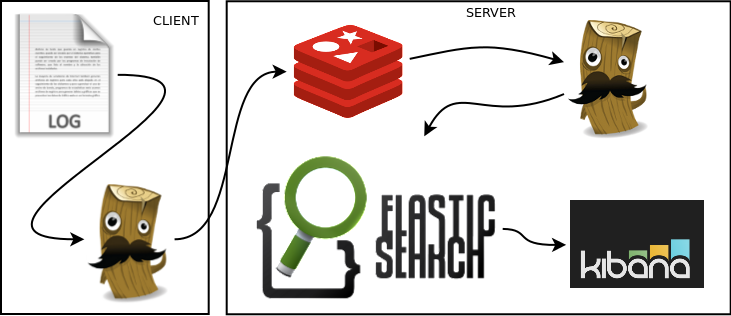
Hay que tener cuidado con redis porque para ganar velocidad almacena en memoria los datos así que en caso de dejar de funcionar el logstash o el elasticsearch durante un período de tiempo prolongado te puedes encontrar con un redis que ocupa en memoria 4GB. Si, también me ha pasado, ... hace una semana (nota mental: volver a poner 4GB de memoria al servidor de logstash ;-) ).
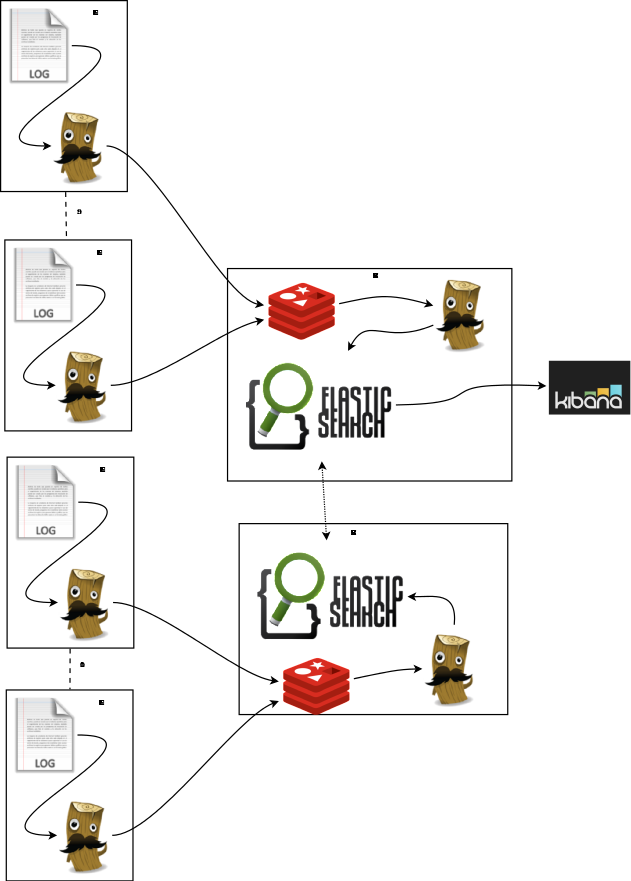
Escalando horizontalmente
|
La alarma que tenemos para la longitud de la cola de redis se dispara y en el kibana vemos datos de lo que pasó hace una hora. El problema puede estar en Logstash o en Elasticsearch así que vamos a crear otra máquina virtual con la pila completa de Redis, Logstash, Elasticsearch en cluster con el otro y un Kibana. ¡Cuidado! Para escalar realmente necesitaríamos tocar conceptos como el sharding que se tocarán en un artículo posterior. Aquí vamos a crear un conjunto de réplica entre dos servidores de Elasticsearch. ¿Has replicado ya el entorno anterior? ¿Y a qué estás esperando? Cuando tengas los dos servidores de Elasticsearch levantados en la misma red verás con sorpresa que ¡Ya están en el conjunto de réplica! Abre los kibanas de ambas instancias y verás como ves los mismos datos. |
|
Este fue el detonante que me impulsó a meterme en el mundo NoSQL. Yo que vengo de un mundo de almacenamientos compartidos, clusters RedHat, IPs flotantes, réplicas que no se recuperan automáticamente en caso de caída de un maestro ... y va este y se configura sólo con un doble click sin pedirle permiso al sistema operativo.
Configuración de Elasticsearch
Su configuración por defecto está escuchando a que alguien dentro del cluster "elasticsearch" se anuncie por multicast. Cuando eso ocurre los dos servidores se sincronizan y a partir de ahí los datos que insertas en un servidor están disponibles en el otro un segundo más tarde.
La configuración más relevante que puedes encontrar en /etc/elasticsearch/elasticsearch.yml y que permite este comportamiento es la siguiente:
cluster.name: elasticsearch discovery.zen.ping.multicast.enabled: true
Con un rápido vistazo en el archivo de configuración podrás ver entre otras cosas que también puedes utilizar unicast para la configuración entre los nodos en caso de que estés usando una red que no permita usar multicast o servidores en la nube como por ejemplo dos instancias de Amazon EC2.
Plugin para ver el estado del cluster en un navegador
Con el plugin elasticsearch-head podemos ver el estado del cluster y gestionarlo desde un navegador.Solución a problemas que te acabarán ocurriendo
Antes de nada ten presente que logstash crea una "base de datos", que en elasticsearch se llama indice, cada día. Supongo que hace esto para que el indice de logs no crezca hasta el infinito haciéndose inmanejable. Puedes ver los que ha ido creando en /var/lib/elasticsearch/elasticsearch/nodes/0/indices/.
Too many open files
Te pasará más o menos en el momento en que todo el mundo se haya acostumbrado a usar el kibana y se haya convertido en una aplicación crítica para la empresa pero no tengas sufiente experiencia para solucionar el problema rápidamente. Como será algo con lo que no contabas probablemente tampoco tengas tiempo para solucionarlo. Eso fue lo que me pasó a mi.
La causa del problema es que cada vez que logstash crea un índice en elasticsearch éste crea y mantiene abiertos un porrón de archivos. En mi caso para el índice logstash-2014.07.08 tiene abiertos 62 archivos:
root@path-precise:/etc/elasticsearch# lsof | grep /var/lib/elasticsearch/elasticsearch/nodes/0/indices/logstash-2014.06.26 | wc
62 558 10582
root@path-precise:/etc/elasticsearch#
Como además la configuración por defecto de elasticsearch crea tres shards el número de archivos abiertos se triplica. No voy a explicar esta afirmación. Veremos que es un shard en un artículo posterior.
Llegar al límite de 1024 archivos, se llega bastante rápido así que deberás realizar estas tres cosas en el servidor:
- Reducir el número de shards a 1: Si tu elasticsearch va sobrado de capacidad en el archivo de configuración de elasticsearch /etc/elasticsearch/elasticsearch.yml, sección Index, deja la siguiente configuración:
index.number_of_shards: 1 index.number_of_replicas: 0
- Desactivar o eliminar los indices que no utilices: esto hará que la información de los mismos no esté accesible pero tampoco se abran los archivos que componen el indice:
- Desactivar un indice:
curl -XPOST 'localhost:9200/logstash-2014.06.26/_close'
- Eliminar un indice:
curl -XDELETE 'http://localhost:9200/logstash-2014.06.26/
- Desactivar un indice:
- Aumentar el límite de archivos abiertos en el /etc/security/limits.conf: se puede aumentar agregando las líneas:
logstash hard nofile 32000 logstash soft nofile 32000
Se me ha llenado el disco y ahora elasticsearch no arranca
No digo que me haya pasado, porque si me hubiera pasado significaría que no tenía bien monitorizada la máquina y que no me habría dado cuenta cuando ocurrió, pero en el hipotético caso de que me hubiera pasado, que no digo que me haya pasado, lo que hay que hacer es arreglar o borrar unos archivos de datos que se han corrompido.
Elasticsearch, antes de insertar datos de verdad, los guarda en unos archivos de texto que usa como si fuera un buffer. El problema es que al estar el disco lleno esos archivos de texto se corrompen así que cuando Elasticsearch va a leerlos para indexar esos datos no puede hacerlo y se pega un tortazo.
Una vez liberado el disco, el archivo que tienes que arreglar o borrar con la consecuente pérdida de datos está en el directorio translog del indice que de problemas. El log del elasticsearch te dirá cual está fallando. Por ejemplo, si te dice que el shard 0 del indice test está fallando vas a /var/lib/elasticsearch/elasticsearch/nodes/0/indices/test/0/translog y dentro verás que hay dos archivos, un translog-1405060275771 y otro translog-1405060275771.recovering. El que tienes que arreglar o borrar es el que se apellida .recovering .
El álbum de hoy
Shedneryan debe ser la obra que más he escuchado de Jamendo (caché). Ideal para trabajar:
Espero que este artículo te haya servido de ayuda.