| Vamos a ver como servir modelos con ollama usando kubernetes para desplegarlo. |

|
Kubernetes y la gpu
Vamos a usar microk8s, que viene con todas las distribuciones. También funciona en windows y mac usando multipass.
En ubuntu habría que ejecutar:
sudo snap install microk8s --classic --channel 1.26/stable sudo snap install kubectl --classic sudo snap install helm --classic mkdir .kube microk8s.config > .kube/config
La versión es muy importante. En la 1.28 las cosas cambian ligeramente así que usa esa. Más adelante te explico los cambios para la 1.28 .
Ahora instalamos el operador de nvidia para dar soporte a la gpu en kubernetes:
microk8s enable gpu
Y con esto ya deberíamos tener un montón de pods que hacen cosas en el namespace gpu-operator-resources. Tienes que esperar a que todos hayan arrancado bien. Si no lo han hecho lo que viene a continuación funcionará, pero usando la CPU.
ollama
Queremos servir un api, como en el post anterior, pero desde kubernetes usando un ingress ... de momento sin autenticar. Y también queremos que se baje los modelos una vez, no que caca vez que se muera el pod tenga que bajarse 10GB, así que instalamos los siguientes addons:
microk8s enable ingress microk8s enable hostpath-storage
Ahora instalamos el chart de ollama:
helm repo add ollama-helm https://otwld.github.io/ollama-helm/
helm repo update ollama-helm
echo """
ollama:
gpu:
enabled: true
type: nvidia
number: 1
# models:
# - llama:7b
#runtimeClassName: "nvidia"
ingress:
enabled: true
hosts:
- host: ollama.127-0-0-1.nip.io
paths:
- path: /
pathType: Prefix
persistentVolume:
enabled: true
""" > values.yaml
helm upgrade --install ollama ollama-helm/ollama \
--namespace ollama --create-namespace \
--values values.yaml
Aquí hay dos detalles que no se le escapan a nadie: he comentado los modelos y el runtimeClassName. Lo primero es porque a fecha de 20240331 el chart tiene un bug que hace que no sea capaz de bajarse los modelos y no arranca. Lo segundo es por la 1.28 de kubernetes, que no sabrá sobre que gpu ejecutar el modelo porque ... ya sabes ... ¿quien no tiene 3 GPUs de 3 marcas distintas en sus ranuras PCI ... hay que especificar. ;-)
Seguro que te has leído mi post anterior y tienes el cliente de ollama ya instalado, pero por si no lo tuvieras:
curl -fsSL https://ollama.com/install.sh | sh sudo systemctl stop ollama sudo systemctl disable ollama export OLLAMA_HOST=http://ollama.127-0-0-1.nip.io
Si solo vas a usar kubernetes con ollama, como es mi caso, puedes agregar esa última línea al $HOME/.bashrc.
Ahora nos bajamos los modelos:
ollama pull llava ollama pull llama2
Con esto tenemos llava que es multimodal y más adelante usaremos para trastear con imágenes, y llama2, que es solo para texto.
Ahora ejecuta la línea del echo:
$ echo "Contesta en español a esta pregunta: ¿Como te va la vida?" | ollama run llama2 Buena pregunta! Como soy una inteligencia artificial, no tengo una vida personal o emocionales, ya que no tengo un cuerpo ni una mente humana. Mi función es procesar información y responder a preguntas de manera objetiva y precisa. Entonces, la vida me va perfectamente, ya que puedo dedicarme exclusivamente a ayudar a las personas a obtener información útil y resolver problemas complejos. ¿Hay algo más en lo que pueda ayudarte?
Dale varias veces y te dará diferentes contestaciónes en función de ... no lo se ... pero algo te va a contar.
Si quieres probar llava, te puedes bajar una foto, como por ejemplo la que está en la cabecera del artículo de los 50 millones de Clicars y pedirle que la describa:
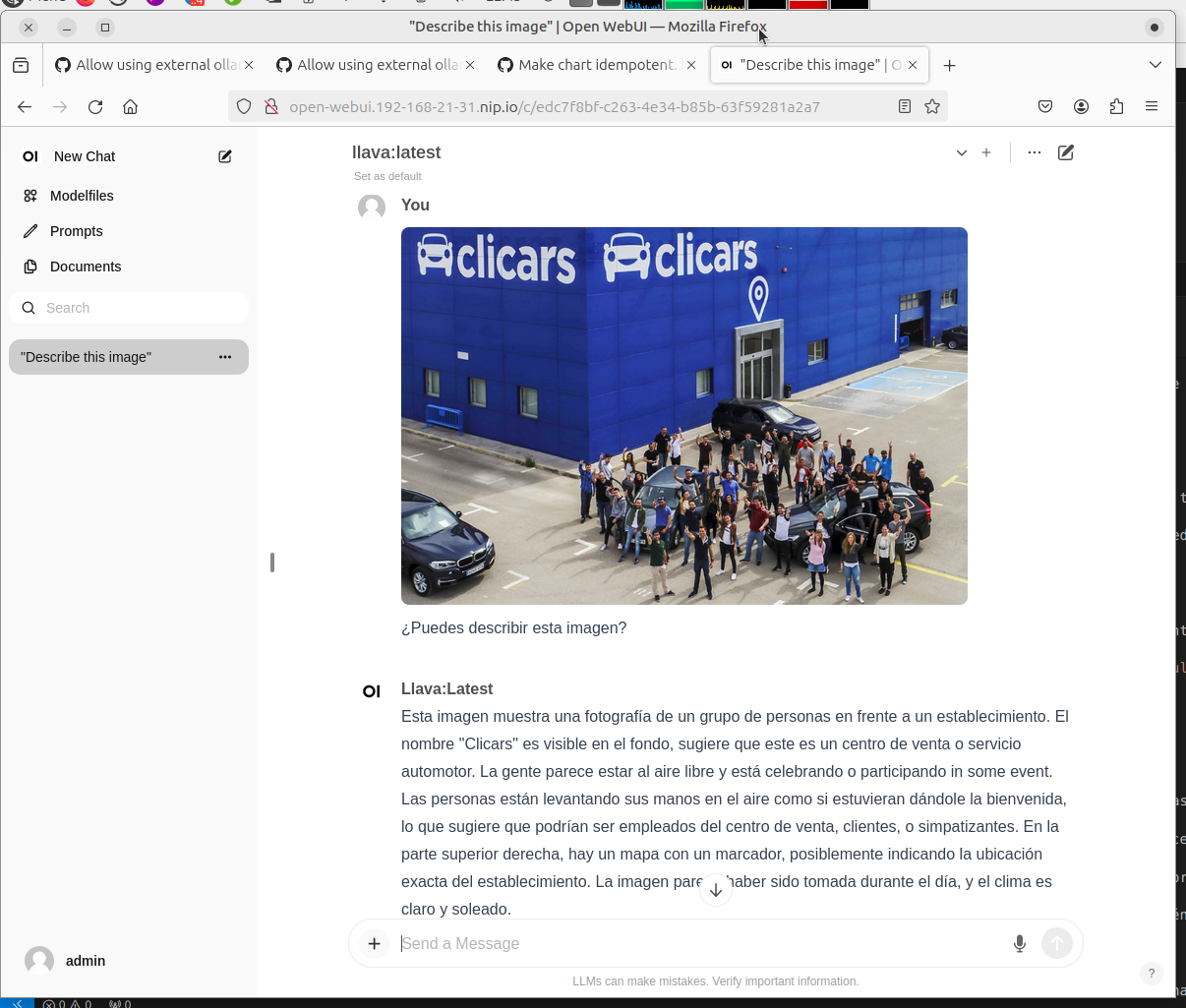
$ wget https://www.clicars.com/blog/wp-content/uploads/2017/03/thumb-post4.jpg $ echo "Contesta en español a esta pregunta: ¿Puedes describir esta imagen? ./thumb-post4.jpg" | ollama run llava Added image './thumb-post4.jpg' Esta imagen muestra una escena en un establecimiento de automóviles. En el centro de la imagen, hay varias personas que parecen estar celebrando o realizando algún acto juntas. Las personas están al aire libre y están levantando sus manos en un gesto comúnmente asociado con victoria o celebración. El establecimiento de automóviles se llama "Clicars", como indica el signaje visible en la imagen. El nombre del negocio está prominente y es una marca reconocida en España. Además, hay un vehículo parqueado en el fondo de la imagen, lo que sugiere que este establecimiento también tiene un salón de venta de automóviles donde se pueden ver varios modelos de coches. La imagen parece haber sido tomada durante el día, ya que los personajes están sombrinados y hay una luz natural visible en el cielo. La escena sugiere un evento o acto realizado por la empresa "Clicars", pero no hay información adicional en la imagen para proporcionar más detalles específicos sobre el evento concreto.
Para que tengas una referencia, este modelo se está ejecutando en una 1050ti con 2GB de nvram y tarda unos 6 segundos en dar unas respuestas bastante correctas ... tiene faltas de ortografía, pero nada muy extremo.
open-webui
Es una ui web que empezó llamándose Ollama WebUI pero el proyecto se está volviendo más ambicioso para permitir interaccionar con cualquier api como la de Stable Diffusion.
Cuando fui a hacer el artículo no se podía usar un ollama externo pero les hice un par de merge request y tardaron nada en mergearlas. :-) Más majos que las pesetas:
- https://github.com/open-webui/open-webui/pull/1464
- https://github.com/open-webui/open-webui/pull/1466
Todavía no ha dado tiempo a subir el chart a artifacthub.io así que clonamos el repositorio y lo instalamos:
git clone --branch dev https://github.com/open-webui/open-webui.git helm upgrade --install open-webui --namespace open-webui --create-namespace \ --set webui.ingress.enabled=true \ --set webui.ingress.host=open-webui.127-0-0-1.nip.io \ --set ollama.externalHost=http://ollama.127-0-0-1.nip.io \ --set ollama.gpu.enabled=true \ open-webui/kubernetes/helm/
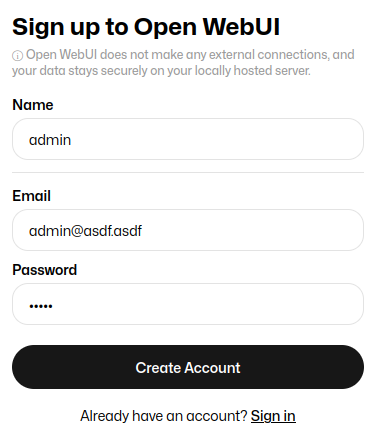
Entras en http://open-webui.127-0-0-1.nip.io y pinchas en "Sign up". La primera cuenta que se cree será la de admin, por ejemplo:
Ahora vamos a hacer lo mismo pero usando open-webui con la foto de antes:
 |
 |
Recursos
La broma te va a salir cara
Gasta muuuuucha memoria y aunque puede funcionar en cpu, para la mayor parte de procesos va a ser inusable por tiempos de respuesta así que te interesará que utilice un hardware específico para ejecutar el runtime. Ahora sería una gpu, pero en breve podrás usar una npu y más adelante ... no soy adivino. Pero el tema es que la broma no te va a salir barata.
Rendimiento
El número de peticiones por segundo que es capaz de gestionar un servicio así es de risa. No estamos hablando de la diferencia de tiempos que puede haber entre dos corredores, sino de la diferencia entre un corredor y un bebé gateando. Además, en las primeras etapas en las que no se sabe manejar los modelos, los tamaños de respuesta pueden ser muy variables por lo que no se puede estimar cuanto va a tardar una petición.
Arquitectura
Ollama sirve un api rest y como seguro que sabes, un api rest NO guarda el estado. Es decir, que los que usen el api van a tener que enviar el contexto una y otra vez, y si el contexto incluye imágenes o archivos grandes, prepárate para un gasto de ancho de banda considerable y tiempos de respuesta muy variables. Como digo depende del servicio pero incluso para un chatbot habría que tenerlo en cuenta por la longitud de las respuestas.
Esto se puede paliar pidiéndole al modelo de forma explícita que te devuelva una respuesta concisa, pero sería interesante pensar en un servicio así como en un servicio asíncrono que pase a través de una cola intermedia. Y no, aumentar el timeout del ingress a 1 hora es una muy mala idea. :-P
La tecnología concreta puede depender tanto del contexto como de lo concisas que sean las respuestas. Si por ejemplo quieres poner un chatbot a lo mejor te interesa guardar el contexto en un redis y ponerle un TTL de un día. Pero si a ese chatbot le quieres agregar la capacidad de comprender imágenes ... meter imágenes en base64 en redis está feo. A lo mejor te interesa guardar las imágenes en un bucket y poner en el bucket el ttl o usar en su lugar mongodb con gridfs poniendo un TTL a los mensajes.
O a lo mejor solo quieres dar respuestas como las de arriba y el contexto te da igual.
Lo único que parece inevitable es esa cola intermedia entre el servicio y ollama.
Algo así:
+---------------+
| redis/mongodb |
+---------------+
^
|
+--------+ +---------+ +--------------------+ +--------+ +--------+
| client |---->| backend |---->| rabbitmq/amq/kafka |<----| AI svc |---->| ollama |
+--------+ +---------+ +--------------------+ +--------+ +--------+
| |
| +--------------------------+ |
+------->| gridfs/s3/object storage |<-----+
+--------------------------+
¡Vaya lío! ¿eh?
Con esto tenemos ...
... kubernetes con el operador de nvidia, el servicio de ollama y open-webui.
Tienes un buen sandbox para trastear.
En el próximo post le daremos un sentido práctico a todo esto.
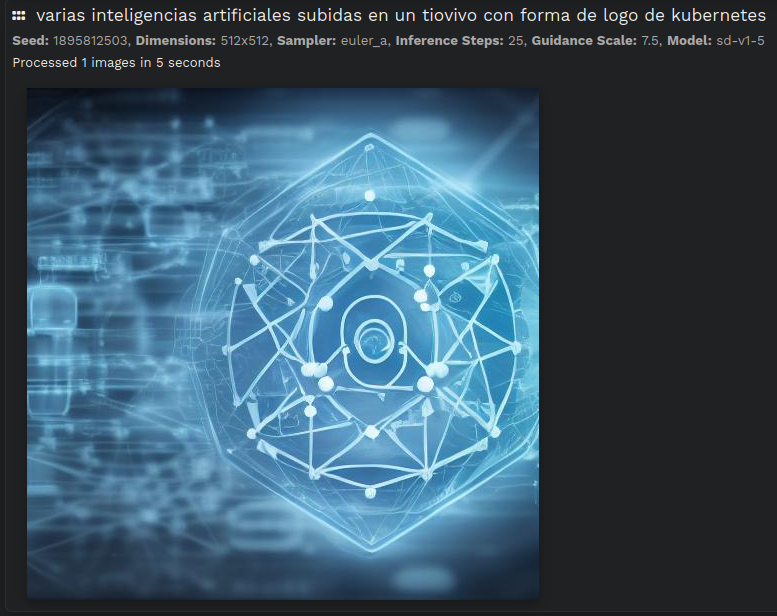
A ver como me defiendes que esto no es, literalmente, creatividad



| Adjunto | Tamaño |
|---|---|
| 388.3 KB | |
| 27.42 KB | |
| 105.26 KB | |
| 553.62 KB | |
| 530.19 KB | |
| 528.93 KB | |
| 415.43 KB | |
| 491.28 KB | |
| 454.4 KB |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}